duplicity/duply: Datensicherung auf die Verlass ist
Bei Dropbox und Co. übernehmen die Cloud-Anbieter die regelmäßige Datensicherung. Wer seine private Cloud betreibt, muss selbst dafür Sorge tragen, dass im Falle von Datenverlust eine Datensicherung vorhanden ist. Bei Homie und Fellow, den beiden private Cloud Servern von datamate, ist dies denkbar einfach. Im Cockpit lassen sich Backups auf FTP-Server, Amazon S3 und USB-Festplatten konfigurieren, automatisieren und überwachen. Die Software, die dahinter steckt, ist duplicity. In diesem Beitrag stellen wir duplicity und sein Frontend duply vor.
Nach der allgemeinen Vorstellung von duplicty und duply folgen die technisch anspruchsvolleren Abschnitte. Eine Zusammenfassung der Befehlszeilenkommandos von duply bildet den Auftakt. Der Befehl zum Aufruf des Backup-Status und die Statusmeldung werden dann im Detail diskutiert. Den Abschluss bildet die Darstellung der Konfiguration von duplicity/duply auf den datamate Servern.
duplicity und duply kurz vorgestellt
Das Python Shell Skript duplicity ist eine simple und dennoch sehr vielseitige und leistungsfähige Software zur inkrementellen Sicherung von Verzeichnissen und den darin enthaltenen Dateien. Es erstellt verschlüsselte Datenpakete (sogenannte Volumes) im TAR-Format und lädt diese auf einen lokalen oder entfernten Dateiserver hoch. Als Verschlüsselung und zur Signierung der Volumes nutzt duplicity GnuPG, eine vollständige und freie Implementierung des OpenPGP Standards, das derzeit als sicher angesehen werden kann und die Daten vor Auswertung und Modifikation schützt. Mit duplicity lassen sich also auch von sensiblen Daten Sicherungen auf öffentliche (unsichere) Servern durchführen.
Nach einem initialen Vollbackup des zu sichernden Datenbestands erstellt duplicity nach einem konfigurierbaren Backup-Plan Kopien der Daten-Änderungen seit des letzten Backuplaufs. Die dafür verwendet libresync-Bibliothek – eine Implementierung des rsync remote-delta Algorithmus von Andrew Tridgell – arbeitet blockbasiert, so dass nur die geänderten Teile von Dateien ins Backup aufgenommen und auf den File Server hochgeladen werden.
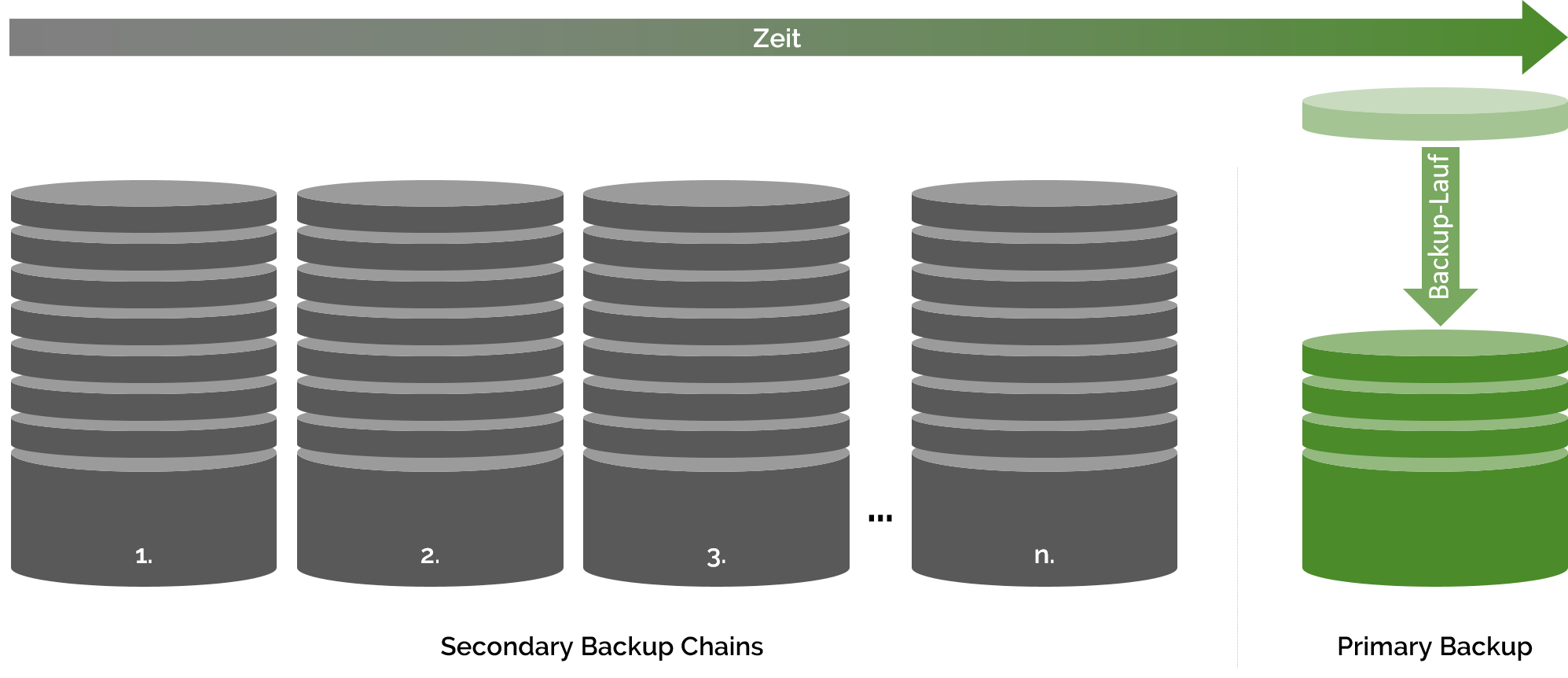
Auf einem Gerät lassen sich mit duplicity eine beliebige Anzahl an Backup-Jobs erstellen. (Ein Backup-Job definiert, wann welche Daten wohin gesichert werden.) In einer Konfigurationsdatei wird für jeden Job das Quellverzeichnis, der Pfad zum Sicherungsziel, die Zugangsdaten sowie die Parameter für die Ausführung des Backups festgelegt. Zu diesen Parametern gehören die Größe der Volumen (Parameter VOLSIZE), die Frequenz von Vollbackups (Parameter MAX_FULLBKP_AGE) und die Anzahl der zu konservierenden Vollbackups (Parameter MAX_FULL_BACKUPS).
Ist das Höchstalter eines Vollbackups erreicht, schliesst duplicity die laufende Backupkette und legt eine neue Backupkette an. Die jeweils aktuelle Backupkette wird bei duplicity Primary Backup Chain genannt. Geschlossene, frühere Backup Chains sind in duplicity-Sprech Secondary Backup Chains (siehe Abbildung). Der Paramter MAX_FULL_BACKUPS legt fest, wieviele solche geschlossenen Ketten gespeichert bleiben, bevor Sie gelöscht werden.
Aktuell unterstützt duplicity unterschiedliche Protokolle zur Verbindung mit File Servern. Neben den Klassikern FTP und WebDAV befinden sich darunter auch Amazon S3, Backblaze2, Dropbox, Google Drive, Microsoft Azure, Rackspace und SwiftStack. Sowie ein gutes Dutzend weitere.
duplicity unterliegt einer GPL-Lizenz und ist damit freie Software. Die aktuelle Version (Stand März 2019) von duplicity ist die Version 0.7.18.2. Die Community Seite von duplicity beschreibt das Programm als “fairly mature software” (ziemlich ausgereifte Software) und untertreibt damit maßlos. duplicity hat einen tadellosen Ruf als grundsolide Software und wird in großen wie in kleinen Installationen erfolgreich eingesetzt. Ein weiteres Zeichen für die Solidität von duplicity ist die Tatsache, dass es Bestandteil der drei GNU/Linux-Distributionen Debian, Fedora und Ubuntu ist.
Was ist nun duply? duply ist ein sogenannter Wrapper für duplicity. Es baut auf duplicity auf (setzt es vielmehr voraus) und macht seine Nutzung und Steuerung einfacher und schlanker. Konkret hilft duply, Backup-Einstellungen in Konfigurationsprofilen zu speichern, wiederkehrende Aufgaben skriptbasiert auszuführen und die Zuverlässigkeit von duplicity Backupläufen zu erhöhen, indem Voraussetzungen geprüft werden. duply fügt duplicity also keine Funktionen hinzu, sorgt aber für eine bequemere Verwendung. Daher steht duply auch für “simple duplicity”.
Kommandozeilen-Action
In der populären Desktop-Umgebung Gnome für Linux steht mit Déjà-Dup eine graphische Benutzeroberfläche für duplicity zur Verfügung. In allen anderen Linux-Distributionen bleibt nur die Kommandozeile oder ein Skript, um duplicity zu bewegen. duply macht dies dankenswerterweise recht einfach.
Seinem Namen treu ist die grundsätzliche Kommandostruktur von duply denkbar simpel:
duply [Backupname] [Action]
Der Backupname ist eine frei zu vergebende Beschreibung eines Backup-Jobs. Unterschiedliche Backup-Jobs werden einfach unter unterschiedlichen Namen angelegt. Die Action spezifiziert das auszuführende Kommando. Unterschiedliche Actions können mit dem neutralen Separator _ und den zwei konditionalen Separatoren + (conditional AND) sowie – (conditional OR) verknüpft werden.
Die vollständige Dokumentation der Kommandozeilenbefehle von duply findet sich in den Man-Pages auf der Community Seite von duply. Die sechs wohl wichtigsten Befehle sind create, backup, status, list, fetch und restore (am Beispiel des Backup-Jobs ftp_backup):
duply ftp_backup create: Erstellt einen Backup-Job mit Bezeichnung ftp_backupduply ftp_backup backup: Führt den Backup-Job ftp_backup ausduply ftp_backup status: Druckt den aktuellen Status des Backup-Jobs ftp_backup auf den Bildschirm (siehe Abschnitt Auskunftsfreudiges Backup-Tool)duply ftp_backup list > /tmp/ftp_backup_list.txt: Schreibt alle im Backup ftp_backup enthaltenen Verzeichnisse und Dateien in die Textdatei ftp_backup_listduply ftp_backup fetch etc/documents /home/documents/restore: Stellt die letzte Sicherung von /etc/documents in /home/documents/restore wieder herduply ftp_backup restore /home/documents/restore: Stellt die aktuelle Datensicherung des Backup-Jobs ftp_backup in /home/documents/restore wieder her
Die meisten Befehle lasssen sich auch mit Datumsangaben in unterschiedlichen Formaten versehen. duply ftp_backup list 2017/03/03 ist genauso möglich wie duply ftp_backup list 3M. Ersteres listet alle Dateien im Backup am 3. März 2017 auf; letzteres die Dateien im Backup vor 3 Monaten. Die Datumsangaben können auf die Primary Backup Chain genauso wie auf eine Secondary Backup Chain verweisen. Liegt eine Datumsangabe vor einem verfügbaren Backup, dann gibt duply die ältesten verfügbaren Daten aus.
Ebenso wie Datumsangaben funktionieren auch Dateiangaben.
Auskunftsfreudiges Backup-Tool
Ein automatisiertes Backup muss nach der Einrichtung regelmäßig überprüft werden. Blindes Vertrauen in ein einmal erfolgreich eingerichtetes, aber dann unbeobachtet gelassenes Backup ist schon den einen oder anderen teuer zu stehen bekommen. Vollgeschriebene Backup-Speicher, ungültige Zugangsdaten, nicht-erreichbare Netzwerkspeicher – die Gründe für ein Scheitern eines Backuplaufs sind vielfältig. duplicity und duply machen diese Überwachung recht einfach.
Mit dem Befehl duply ftp_backup status wird der Status des Backup-Jobs ftp_backup aufgerufen. Heißt der Backup-Job anders, muss ftp_backup entsprechend ersetzt werden (siehe Abschnitt Kommandozeilen-Action). Die nachfolgende Block ist ein Beispiel für den Status eines eingerichteten und funktionierenden Backups:
Start duply v2.0.1, time is 2018-01-21 11:57:00.
Using profile '/root/.duply/ftp_backup'.
Using installed duplicity version 0.7.12, python 2.7.6, gpg 1.4.16 (Home: ~/.gnupg), awk 'GNU Awk 4.0.1', grep 'grep (GNU grep) 2.16', bash '4.3.11(1)-release (x86_64-pc-linux-gnu)'.
Signing disabled. Not GPG_KEY entries in config.
Checking TEMP_DIR '/tmp' is a folder and writable (OK)
Test - Encryption with passphrase (OK)
Test - Decryption with passphrase (OK)
Test - Compare (OK)
Cleanup - Delete '/tmp/duply.1330.1516532220_*'(OK)
--- Start running command STATUS at 11:57:00.243 ---
Local and Remote metadata are synchronized, no sync needed.
Last full backup date: Sun Dec 24 01:00:06 2017
Collection Status
-----------------
Connecting with backend: BackendWrapper
Archive directory: /media/disk/duply-cache/duply_backup
Found 2 secondary backup chains.
Secondary chain 1 of 2:
-------------------------
Chain start time: Sun Feb 12 01:00:07 2017
Chain end time: Sun Mar 12 01:00:09 2017
Number of contained backup sets: 5
Total number of contained volumes: 604
Type of backup set: Time: Number of volumes:
Full Sun Feb 12 01:00:07 2017 593
Incremental Sun Feb 19 01:00:09 2017 2
Incremental Sun Feb 26 01:00:05 2017 3
Incremental Sun Mar 5 01:00:06 2017 1
Incremental Sun Mar 12 01:00:09 2017 5
-------------------------
Secondary chain 2 of 2:
-------------------------
Chain start time: Sun Mar 19 01:00:06 2017
Chain end time: Sun Apr 16 01:00:05 2017
Number of contained backup sets: 5
Total number of contained volumes: 610
Type of backup set: Time: Number of volumes:
Full Sun Mar 19 01:00:06 2017 603
Incremental Sun Mar 26 01:00:09 2017 1
Incremental Sun Apr 2 01:00:13 2017 2
Incremental Sun Apr 9 01:00:04 2017 2
Incremental Sun Apr 16 01:00:05 2017 2
-------------------------
Found primary backup chain with matching signature chain:
-------------------------
Chain start time: Sun Apr 23 01:00:06 2017
Chain end time: Sun May 14 01:00:05 2018
Number of contained backup sets: 4
Total number of contained volumes: 617
Type of backup set: Time: Number of volumes:
Full Sun Apr 23 01:00:06 2017 608
Incremental Sun Apr 30 01:00:06 2018 5
Incremental Sun May 7 01:00:05 2018 3
Incremental Sun May 14 01:00:05 2018 1
-------------------------
No orphaned or incomplete backup sets found.
--- Finished state OK at 11:57:42.092 - Runtime 00:00:41.849 ---
Die wichtigste Zeile des Status befindet sich ganz am Ende der Statusmeldung: No orphaned or incomplete backup sets found. duplicity meldet also zurück, dass es keine Probleme bei der Ausführung des Backup-Jobs hatte. Aus dem Status sieht man aber noch mehr als nur den Gesundheitszustand des Backups. Man sieht z.B. wann die Backupläufe erfolgt sind. In diesem Beispiel wird leicht ersichtlich, dass das Backup offensichtlich per Cron-Job jeweils Sonntags um 1Uhr morgens ausgeführt wurde. Mit wenig Mühe sieht man auch, dass sich das Backup dieses Beispiels in der dritten Backup Chain befindet. Zwei Secondary Chains wurden bereits abgeschlossen.
Angesichts der wachsenden Total number of contained volumes (Gesamtanzahl der enthaltenen Volumen) lässt sich auch erkennen, dass das Backup in Größe zunimmmt – wie in den meisten Fällen zu erwarten ist. Eine Größenabschätzung des Speicherbedarfs für das Backup ist über diese Zahl auch möglich. Ist die Volume-Größe in dem Backup-Profil auf 50MB festgelegt, dann ist der Speicherbedarf rund 50MB multipliziert mit der Total number of contained volumes in allen Backup Chains.
Datensicherung auf Homie und Fellow mit duplicity/duply
Bei Anlage eines Backup-Jobs im Cockpit von Homie und Fellow erfolgen zwei Aktionen. Zum einen wird ein Cron-Job angelegt, der die Backup-Läufe zu den gewünschten Zeitpunkten ausführt. Zum anderen wird unter /root/.duply ein Verzeichnis mit dem Namen des Backup-Jobs angelegt. (Der Punkt vor dem Verzeichnisnamen duply sorgt dafür, dass das Verzeichnis versteckt ist.) Bei einem Backup auf einen FTP-Server ist der Name des Jobs duply_ftp, bei einem Backup auf Amazon Server duply_amaz und duply_hdd bei einer Sicherung auf eine externe Festplatte.
Unabhängig vom Namen des angelegten Verzeichnisses liegen dort mindestens vier Textdateien:
- conf: Konfigurationsdatei des Backup-Jobs
- pre: Vorbereitendes Skript
- post: Nachbereitendes Skript
- exlude: Liste mit vom Sicherungslauf ausgeschlossenen Dateien und Ordnern

Die Abbildung stellt den generellen Ablauf bei Ausführung eines Backup-Jobs auf einem datamate Server dar. Konkret passiert – am Beispiel des Backup Jobs duply_hdd – folgendes: Der Cron-Job stößt die Ausführung des Backups mit dem Befehl duply duply_hdd pre+bkp+post_verify+purgeFull --force an. Die Action pre sorgt dafür, dass zunächst das pre-Skript ausgeführt wird. Dieses kopiert die Seafile-Datenbank und die Konfigurationsdateien von Webserver, OpenVPN und SSH auf /media/disk. Darüber hinaus wird zur einfachen Überwachung des Backups in einer SQL-Datenbank ein Datensatz mit Informationen über das Quellverzeichnis /media/disk und einem Zeitstempel angelegt. Nach erfolgreichem Abschluss des pre-Skripts erfolgt die eigentliche Datensicherung. Dazu wird analysiert, welche Dateien seit dem letzten Lauf neu hinzugekommen und welche Änderungen sich auf /media/disk ereignet haben. Neue Dateien und Änderungen werden auf das in der Konfigurationsdatei spezifizierte Sicherungsziel kopiert – verschlüsselt natürlich. Nach Abschluss des Kopiervorgangs wird über die post-Action das post-Skript von duply ausgeführt. Dieses vervollständigt den Datensatz in der SQL-Datenbank und erfasst neben der Dauer des Backups auch die Anzahl der neu hinzugekommenen, modifizierten und gelöschten Dateien. Schliesslich sorgen verify und purgeFull --force dafür, dass der in der Konfigurationsdatei gesetzte Parameter MAX_FULL_BACKUPS umgesetzt wird.